Rating Algorithmen für Ultimate
angewendet auf DFV-Daten, von René Heß, 13. Januar 2023
Contents
1 Einleitung
2 Rating Algorithmen
2.1 Elo
2.2 Glicko2
2.3 WHR – Whole-History Rating
3 Anwendung auf DFV Daten
3.1 Methodik
3.2 Grafiken – Mixed Outdoor
3.3 Grafiken – Women Outdoor
3.4 Grafiken – Open Outdoor
3.5 Grafiken – Vorhersagequote
3.6 Interpretation
4 Fazit
5 Anhang
1 Einleitung
In vielen Sportarten werde Rating-Systeme eingesetzt um die relative Spielstärke von Spieler*innen oder Teams abzuschätzen und vergleichen zu können. Beispiele dafür finden sich im Schach, Tischtennis, Fußball (World Football Elo Ratings) oder Discgolf. In diesem kurzen Artikel wenden wir verschiedene Rating-Algorithmen auf die Daten der offiziellen DFV-Turniere an und vergleichen die vorhergesagte Spielstärke.
2 Rating Algorithmen
Zuerst stellen wir kurz die untersuchten Rating-Algorithmen vor. Unter einem Rating verstehen wir ein Zahl welche die relative Spielstärke eines Teams in Abhängigkeit von der Zeit beschreibt. Es wurden keine Ranking-Algorithmen betrachtet, welche dafür ausgelegt sind Teams nach Spielstärke in einem abgegrenzten Zeitraum (z.B. ein Turnier, oder eine Saison) zu sortieren. Das Windmill Power Ranking oder das USA Ultimate Ranking sind zwei im Ultimate bekannte Algorithmen- um ein Ranking zu erstellen. Es könnte durchaus möglich sein, über diese Algorithmen ein kontinuierliches Rating herzuleiten, dieser Ansatz wurde aber im Folgenden nicht weiter verfolgt. In den nächsten Absätzen geben wir einen kurzen Überblick über folgende Rating-Algorithmen:
- Elo
- Glicko2
- Whole History Rating (WHR)
2.1 Elo
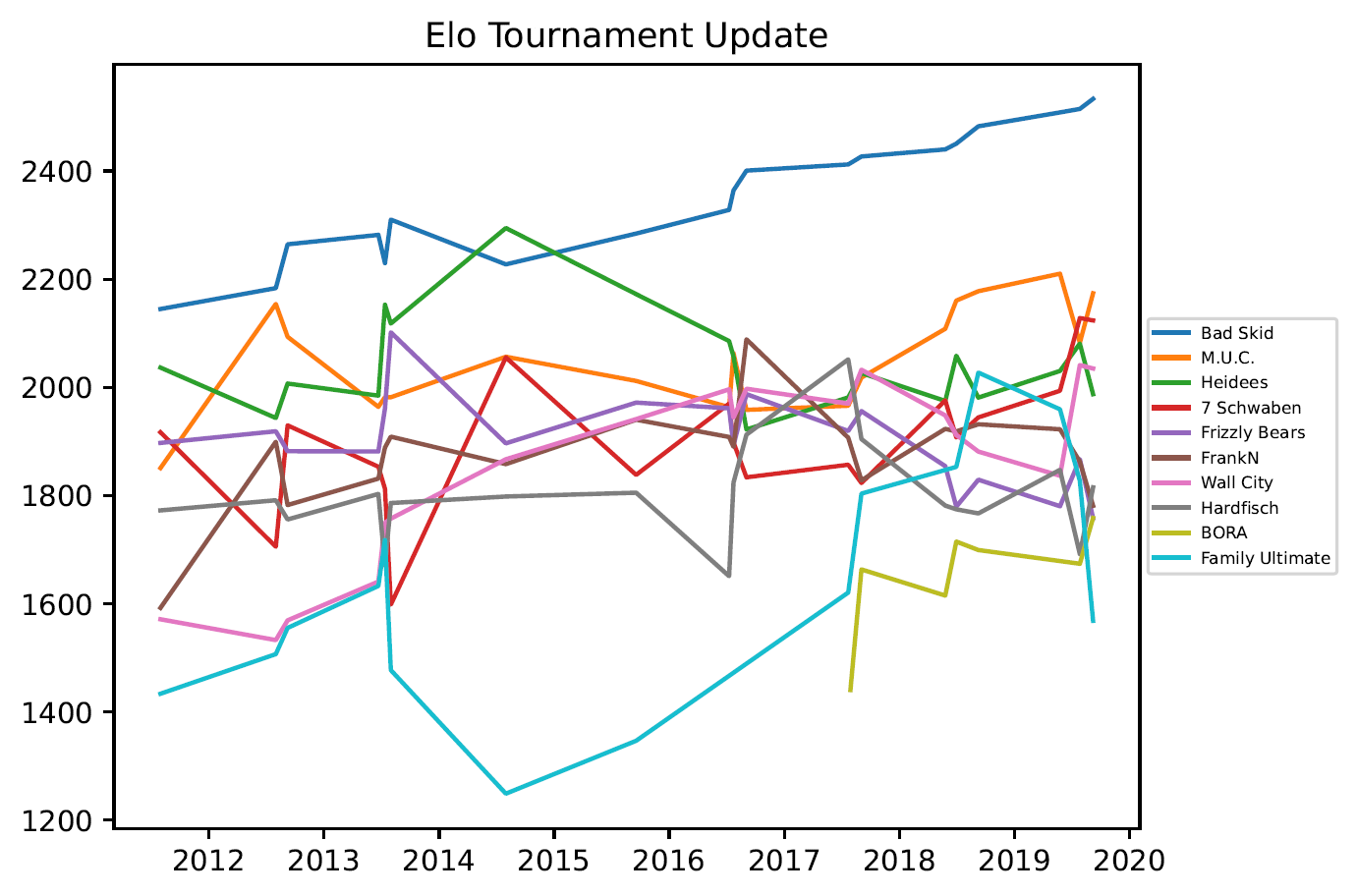
Das Elo-Rating (siehe Wikipedia englisch und Wikipedia deutsch) ist eines der bekanntesten Rating-Systeme und wurde auf viele verschieden Sportarten angewendet und vereint die folgenden Eigenschaften:
- Es ist weit verbreitet und wird seit vielen Jahren in verschiedenen Sportarten verwendet.
- Rating Änderungen lassen sich sehr einfach aus den aktuellen Ratings und Spielergebnissen berechnen.
- Das Rating modelliert Gewinnwahrscheinlichkeiten. Aus den Ratings zweier Teams lässt sich sehr einfach die vorhergesagte Gewinnwahrscheinlichkeit berechnen.
2.2 Glicko2
Glicko2 (vgl. nochmals Elo-Zahl sowie Glicko-System) ist eine Erweiterung des Elo-Systems, bei dem die Rating-Unsicherheit mit modelliert wird. Durch längere Inaktivität steigt die Rating Unsicherheit, was dazu führt, dass sich das Rating schneller verändert. Das ist insbesondere im Kontext von Online Spielen interessant, wo es üblich ist, das Spieler*innen Phasen hoher Aktivität und längere Pausen haben. Für den Ligenbetrieb im Ultimate ist das von geringer Bedeutung, da die teilnehmenden Teams üblicherweise eine vorgegebene Anzahl von Turnierspielen pro Saison abhalten.
2.3 WHR – Whole-History Rating
Das Whole-History Rating (s. Coulom, Rémi. “Whole-history rating: A Bayesian rating system for players of timevarying strength.” International Conference on Computers and Games. Springer, Berlin, Heidelberg, 2008) verfolgt einen leicht anderen Ansatz, indem alle vergangenen Turniere zur Berechnung des Ratings mit einbezogen werden. Dadurch kann eine bessere Abschätzung der Spielstärke erreicht werden. Es ist jedoch mathematisch und algorithmisch deutlich komplexer.
3 Anwendung auf DFV Daten
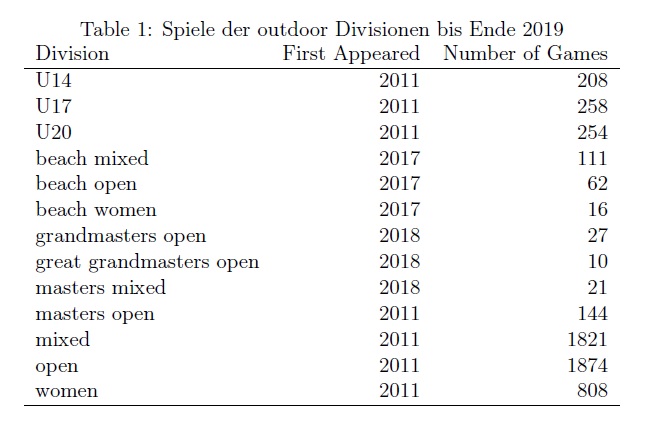
Wir werden die Rating-Algorithmen auf die Spiele der Outdoor Saisons der Divisionen Mixed, Women und Open von den Jahren 2011-2019 anwenden. Tabelle 1 gibt eine Übersicht über alle Outdoor Divisionen und die absolvierten Spiele, für welche Ergebnisse unter scores.frisbeesportverband.de vorliegen. Bevor wir für die einzelnen Division das modellierte Rating betrachten, gehen wir im nächsten Kapitel etwas genauer darauf ein, wie die Grafiken erstellt wurden. Danach folgen Grafiken für die verschieden Divisionen und Algorithmen. Im Unterkapitel 3.5 vergleichen wir die Vorhersagequote der verschieden Algorithmen. Im letzten Unterkapitel folgt eine kurze Interpretation der Ergebnisse. Eine Warnung vorneweg: Sowohl bei der Implementierung als auch bei der Bereinigung der Daten sind mit großer Wahrscheinlichkeit viele Fehler passiert. Die Ergebnisse sind also mit Vorsicht zu genießen.
3.1 Methodik
Bevor wir uns bunte Bilder anschauen, ein paar Worte zur Methodik:
- Es wurden jeweils alle Spiele aller Ligen einer gegebenen Division simuliert.
- Für Elo und Glicko2 wurde ein initiales Rating im Bereich 1000-2000 auf Basis der Platzierungen der Saison 2011 angesetzt. Beginnend mit diesem Rating wurden alle Spiele von 2011-2019 (einschließlich) simuliert.
- Für Elo und Glicko2 gibt es zwei Möglichkeiten das neue Rating zu berechnen: Eine Möglichkeit ist eine Anpassung nach jedem einzelnen Spiel. Durch die Wochendturniere ergeben sich dadurch sehr viel Rating Schwankungen an sehr wenigen Tagen im Jahr. Ein anderer Ansatz ist ein Rating Update nach dem Turnierwochenende, auf Basis aller Ergebnisse dieses Wochenendes. In den Plots werden diese beiden
Ansätze als “tournament update” und “single game update” bezeichnet. - Das Elo Verfahren enthält einen Parameter welcher festlegt, wie schnell sich das Rating ändern kann. Dieser Parameter wurde empirisch sinnvoll gewählt, siehe Anhang.
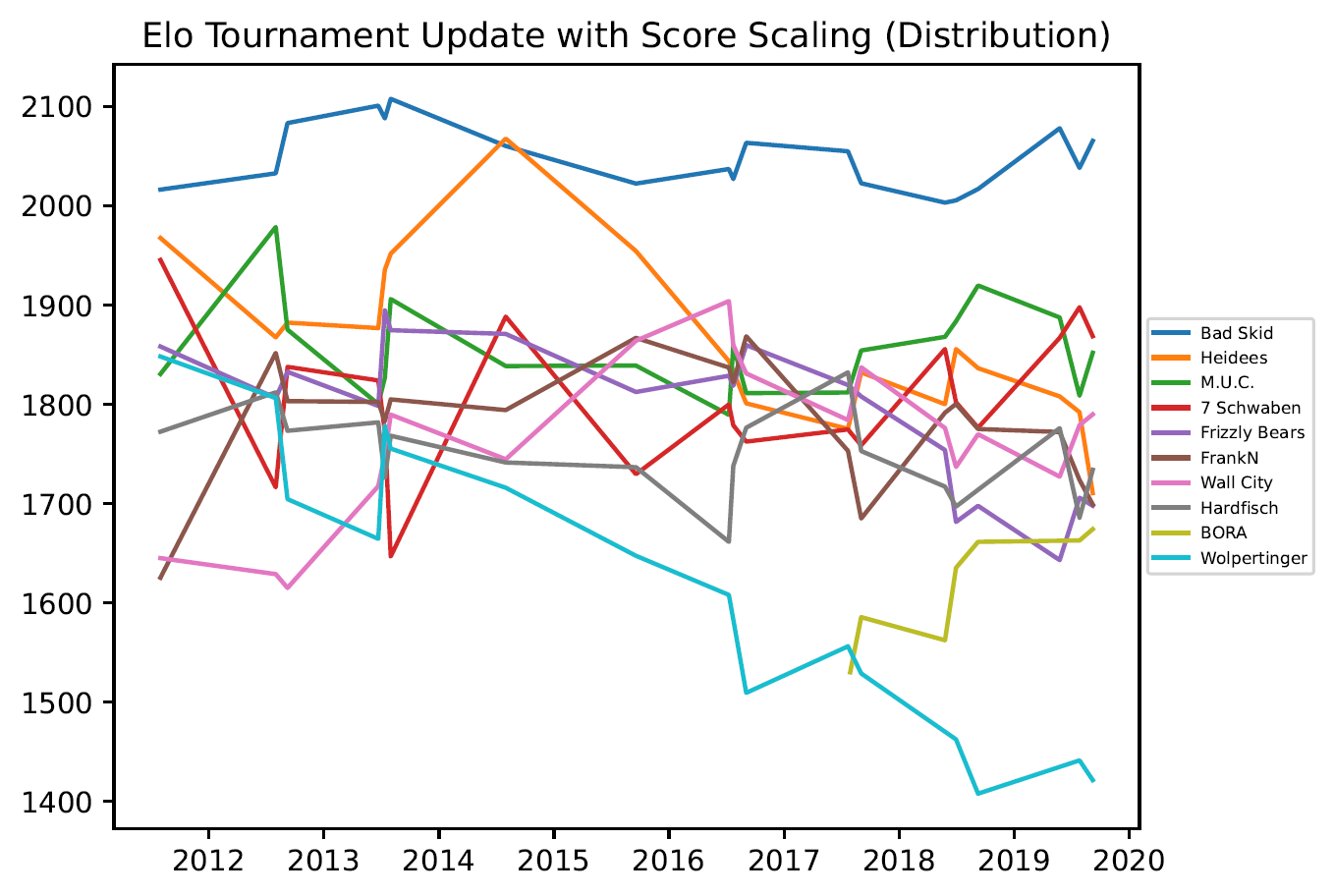
- Manch Elo Verfahren sind mit “score scaling” beschriftet. In diesem Fall wurde die Punktedifferenz als Gewichtung beim Rating Update mit einbezogen, ähnlich zur Tordifferenz hier. Dabei wurden unterschiedlicheGewichtungen ausprobiert. Da dieser Ansatz zu keiner wesentlichen Verbesserung der Vorhersagequote führt, wird er hier nicht weiter erläutert.
- Der Glicko2 Algorithmus hängt sogar von zwei Parameters ab. Es wurde kein Versuch unternommen, diese sinnvoll zu wählen, da nicht damit zu rechnen ist, dass für unseren Anwendungsfall Glicko2 deutlich bessere Ergebnisse liefert als Elo. Für die Implementierung wurde https://github.com/deepy/glicko2 verwendet.
- Whole-History Rating braucht weder ein initiales Rating noch eine Parameterwahl.
Bei der Implementierung wurde https://github.com/pfmonville/whole_history_rating verwendet. - Die Daten wurden so weit es in sinnvoller Zeit möglich war von Fehlern bereinigt. Als bestes Beispiel dient vermutlich das Team “Frau Rauscher & The Bembelboyz” welchen in neun Saisons unter sieben verschiedenen Namen im Datensatz auftaucht. Manche Probleme lassen sich aber nicht ohne weiteres beheben, z.B. Teamumbenennungen, Teamvereinigungen, das Aufspalten von Teams und Spiele mit unvollständigen Daten.
- In allen Divisionen werden leider nur die zehn Teams mit der Besten Wertung (gemittelt über die Saisons 2011-2019) angezeigt, da die Grafiken sonst sehr unübersichtlich werden.
- Bei den Grafiken zur Vorhersagequote wird der Anteil der durch das Rating korrekt vorhergesagten Spiele einer kompletten Saison gezeigt.
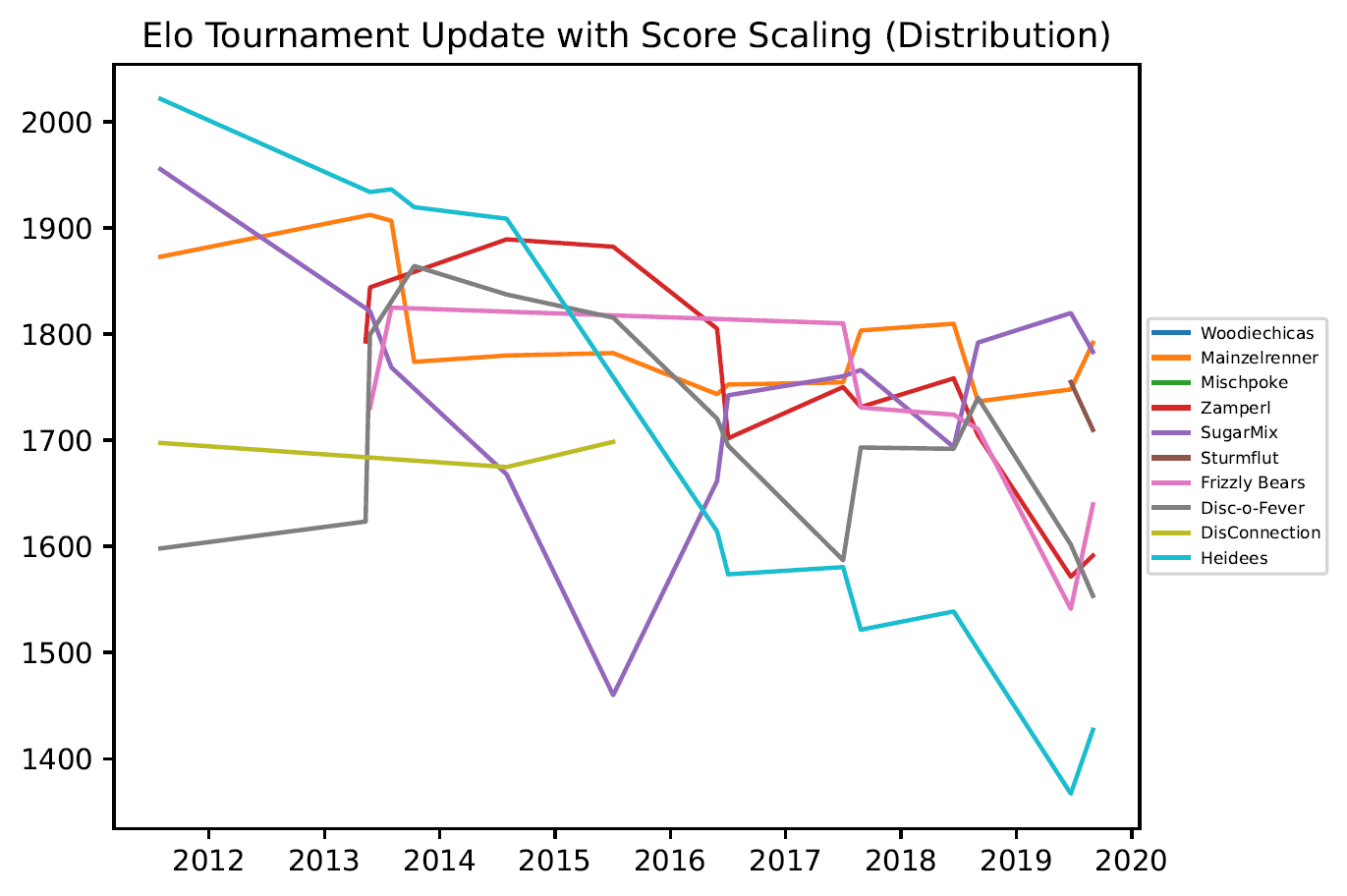
3.2. Grafiken Mixed Outdoor

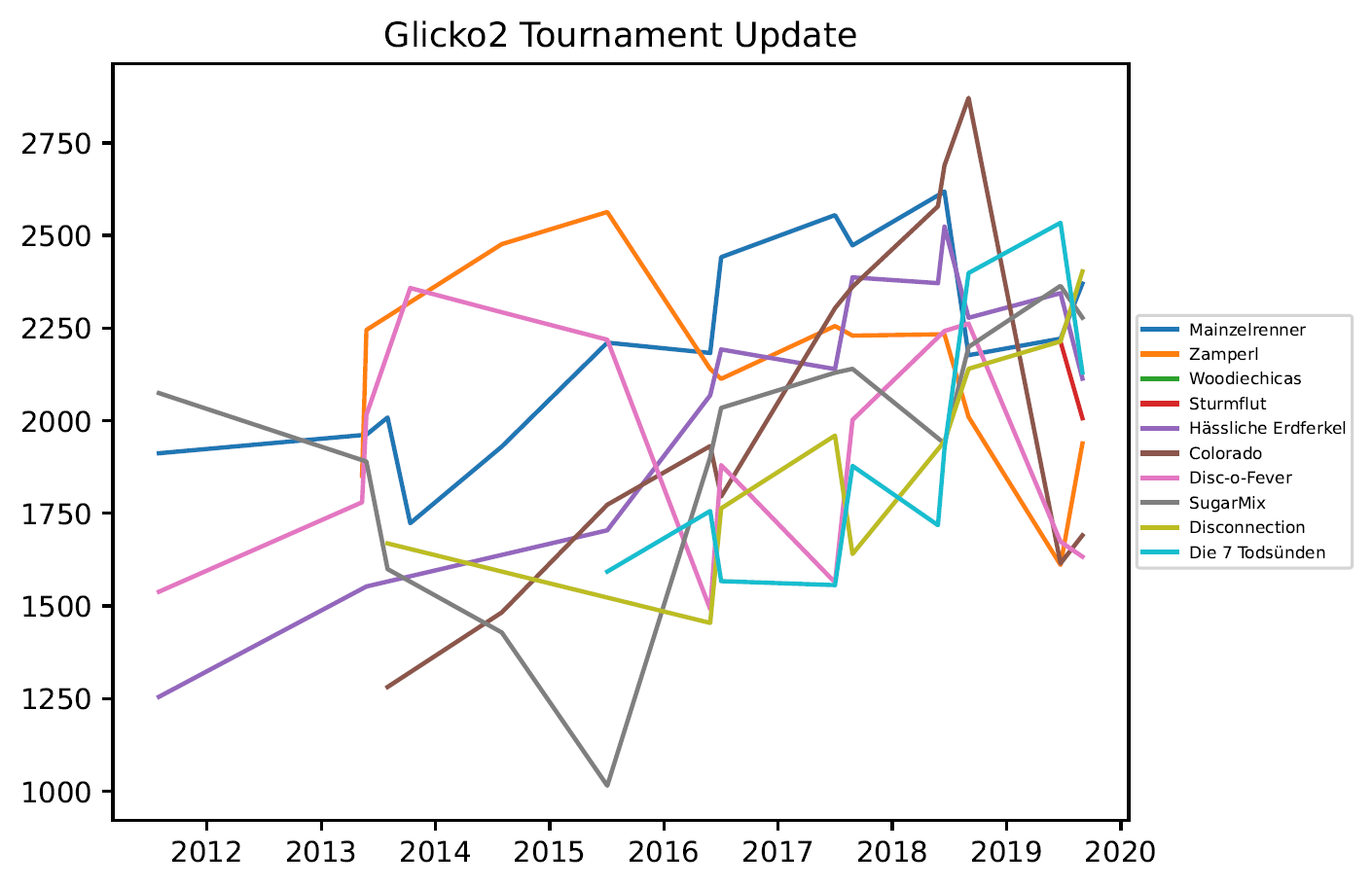
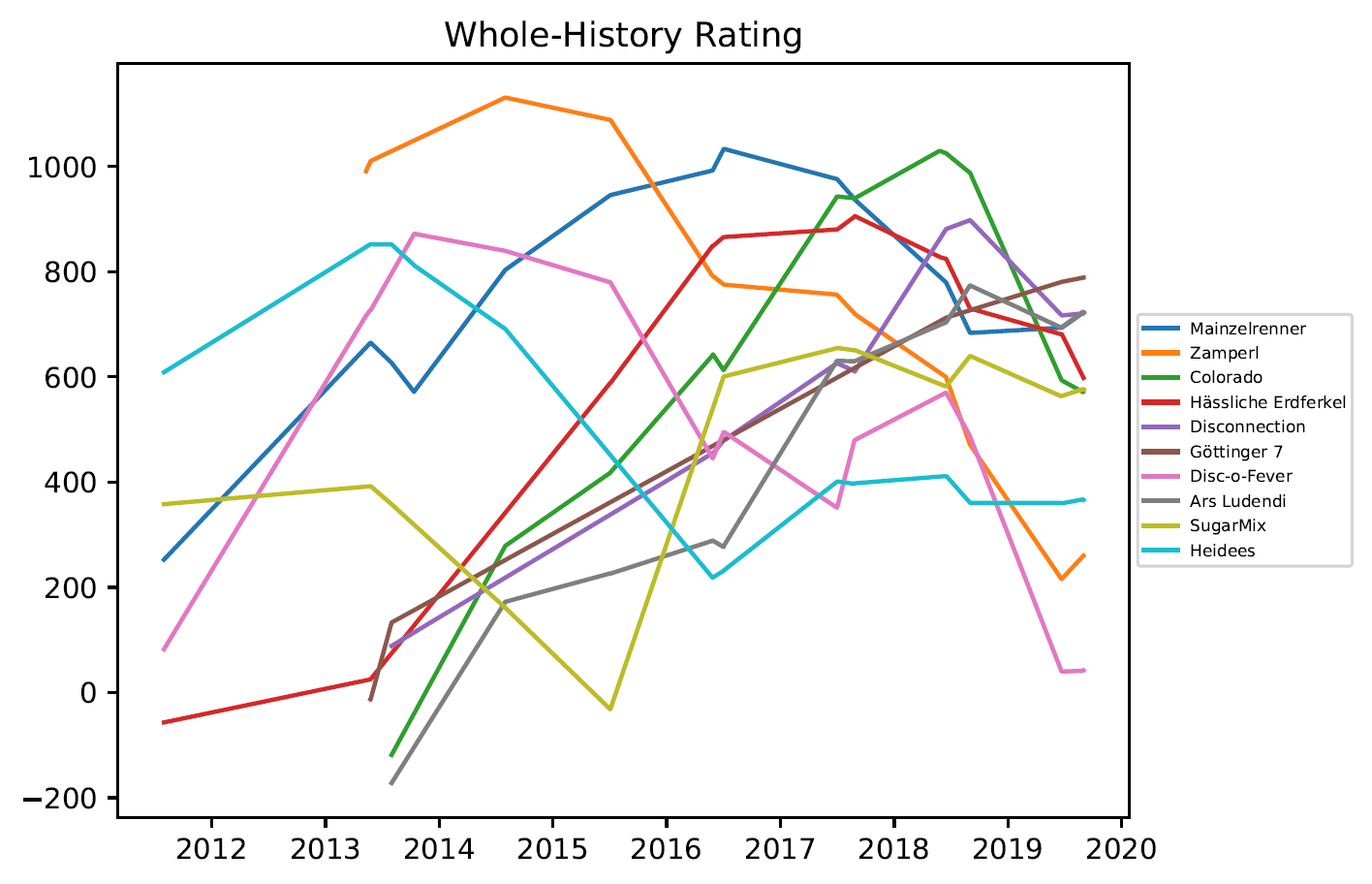
3.3 Grafiken – Women Outdoor
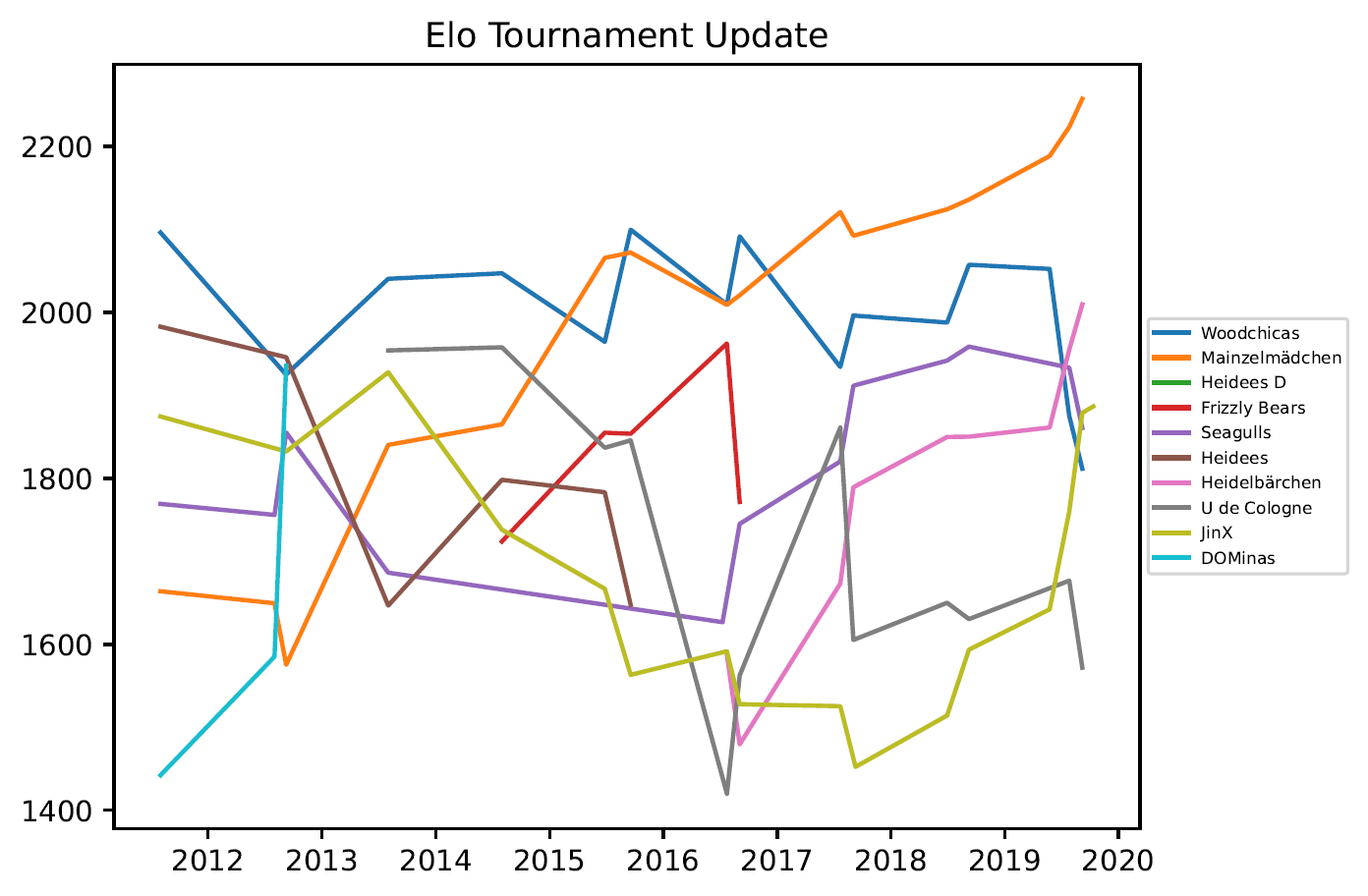
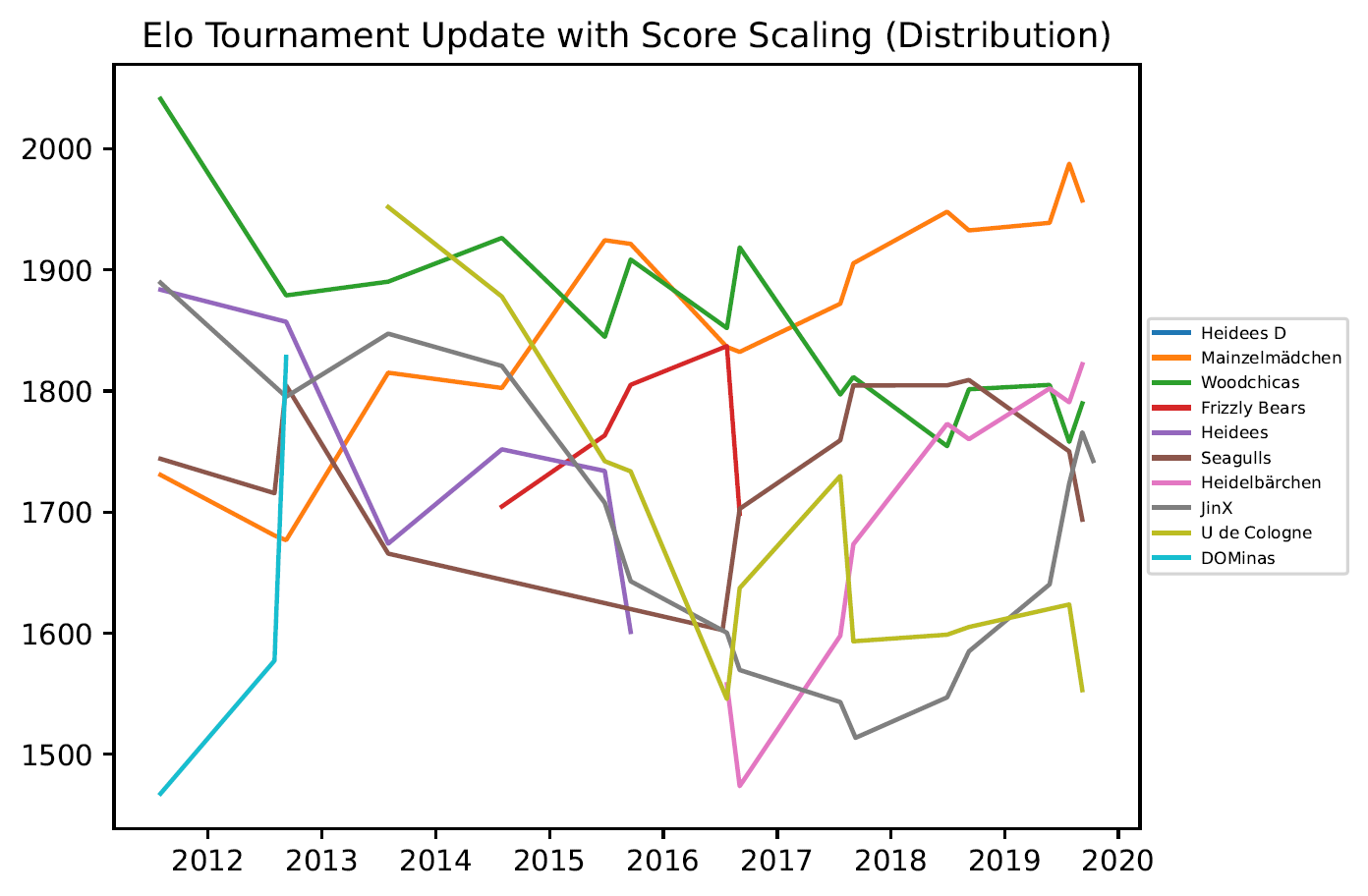
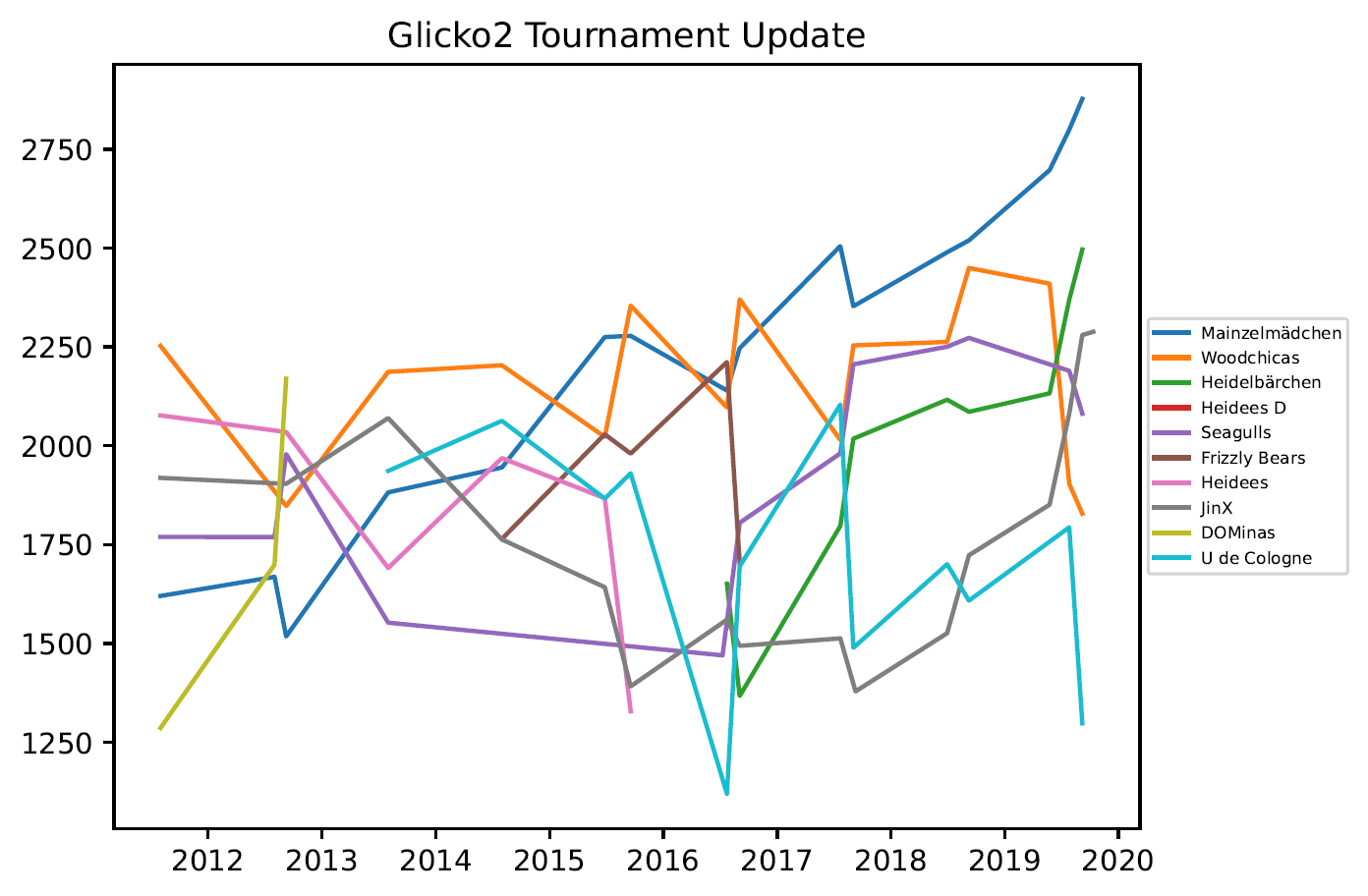
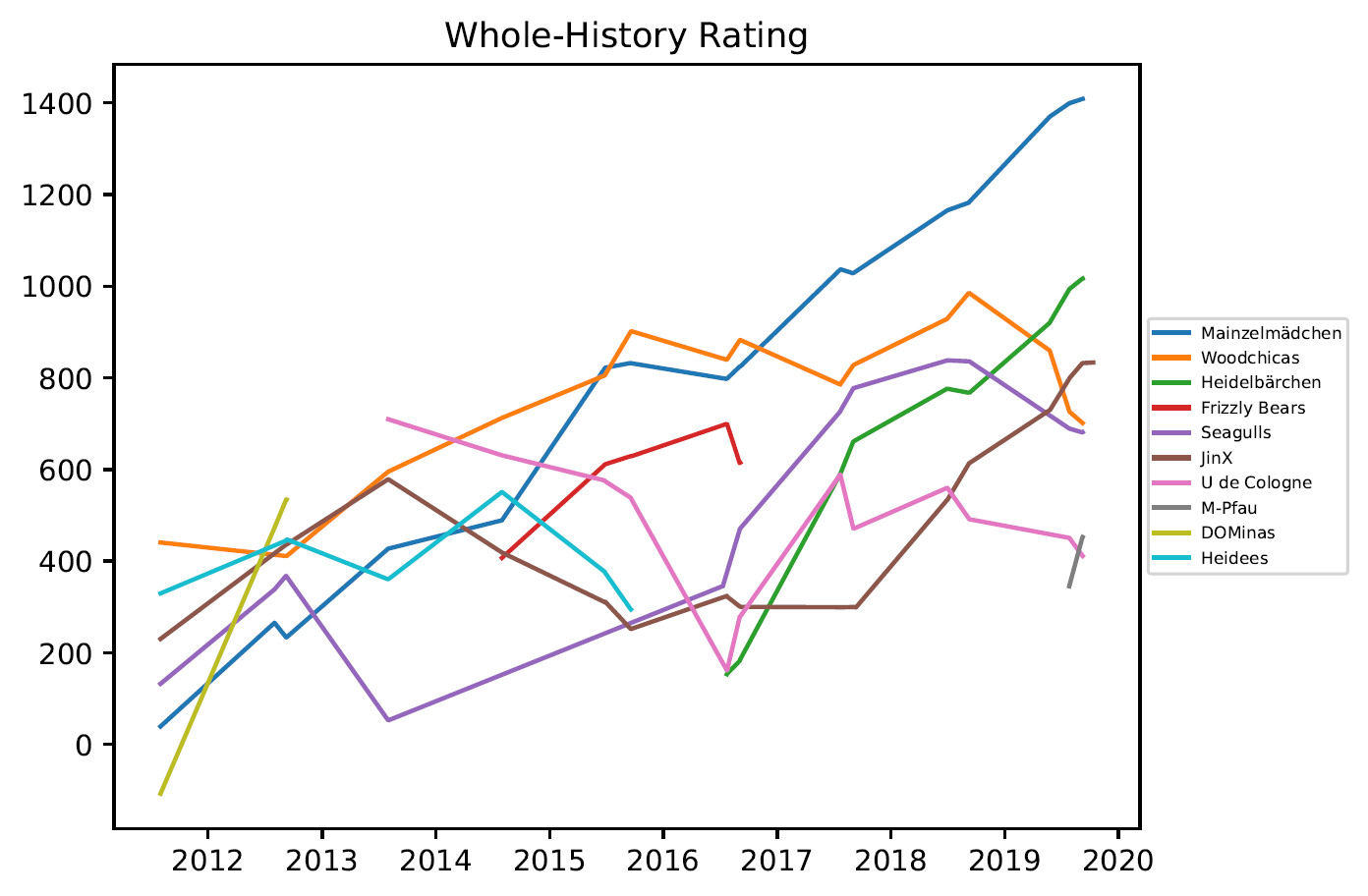
3.4. Grafiken – Open Outdoor
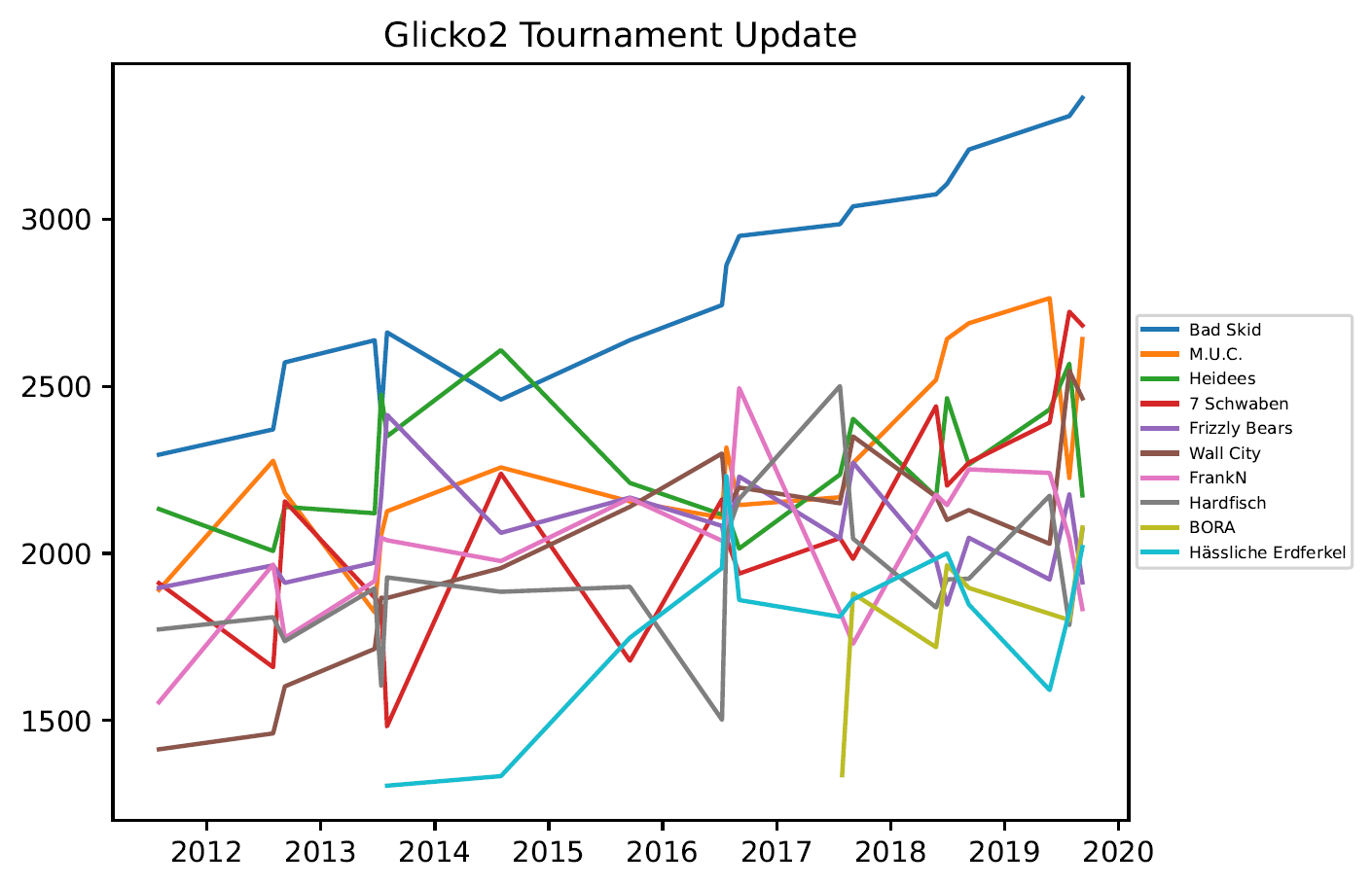
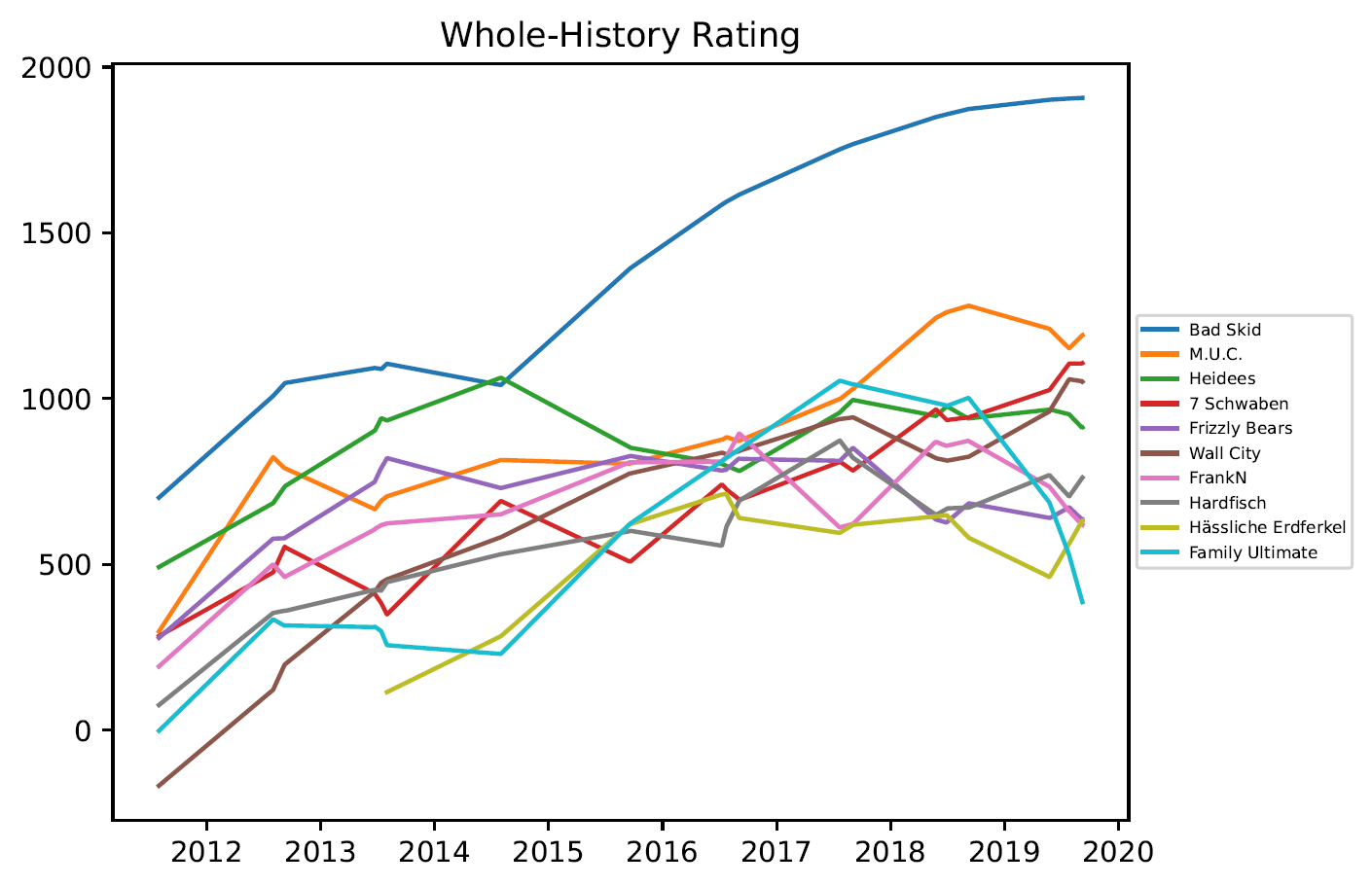
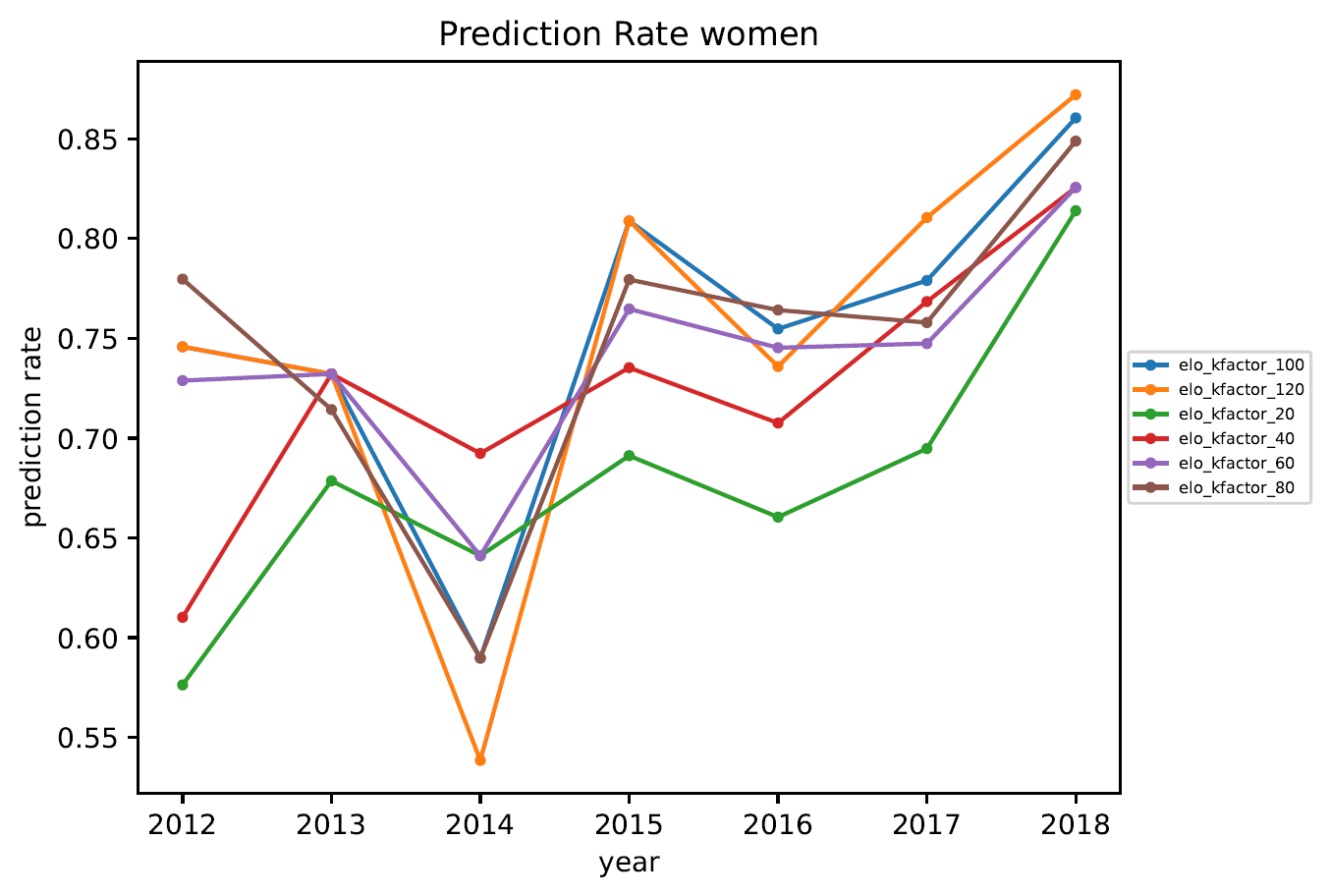
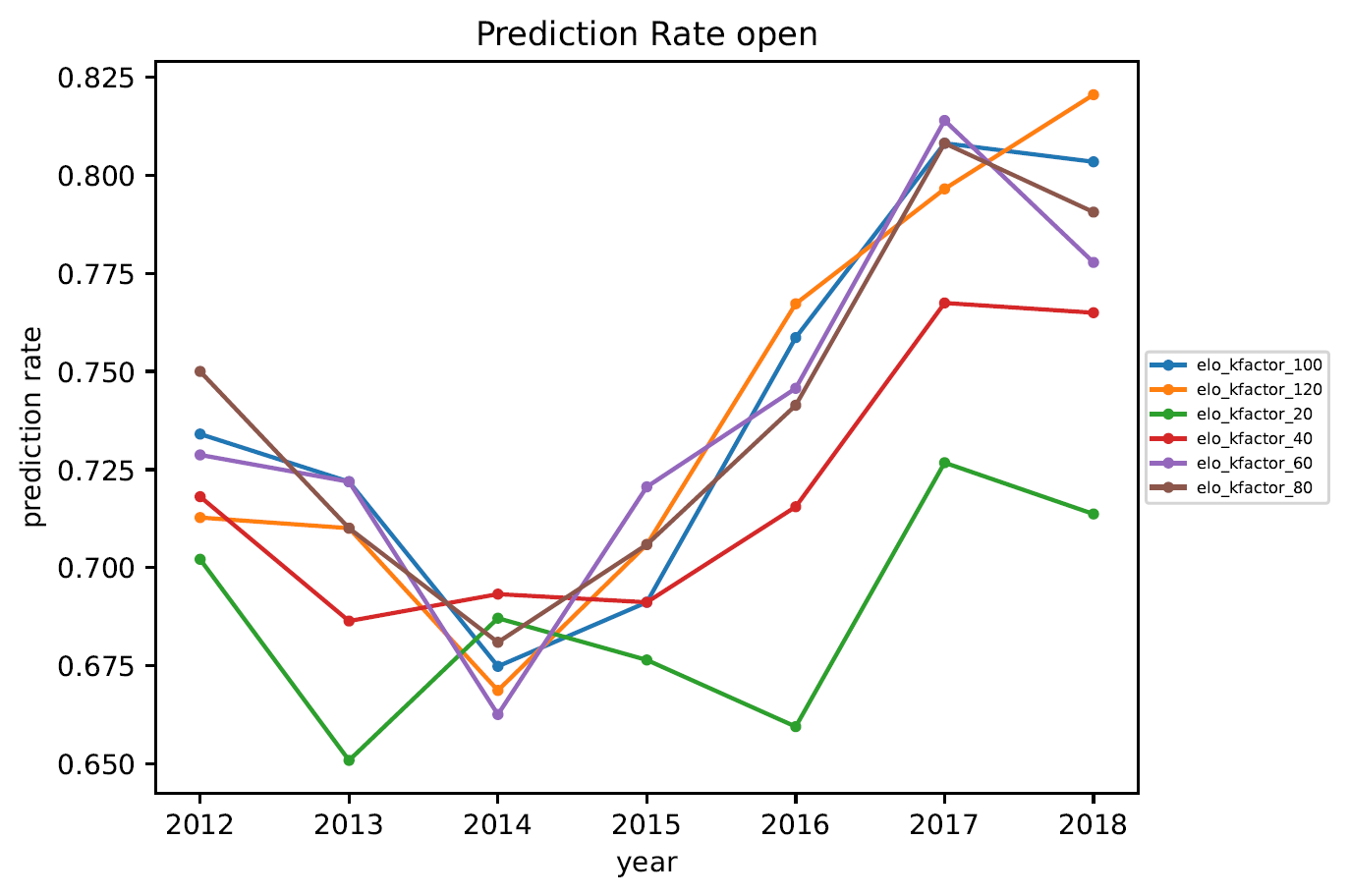
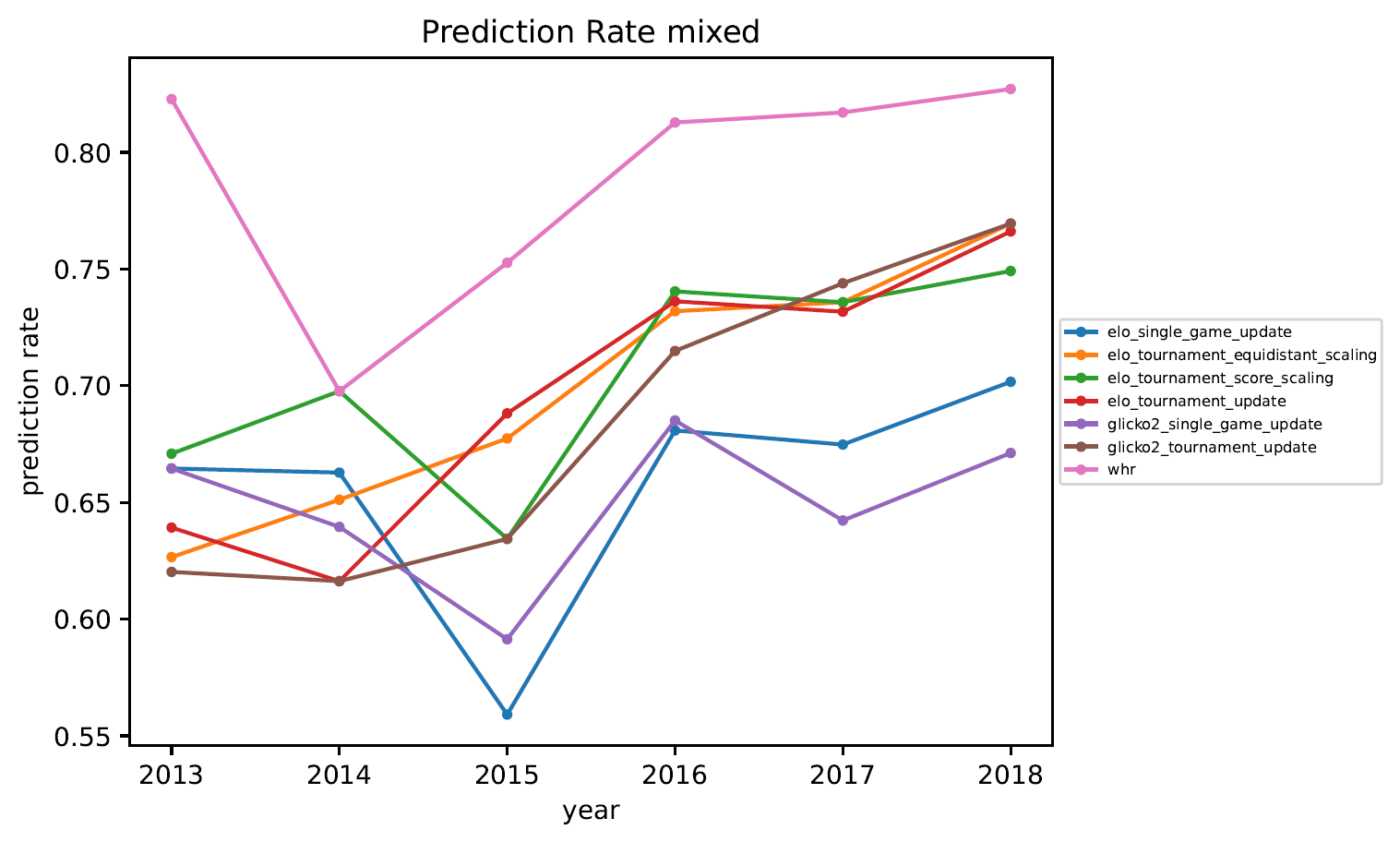
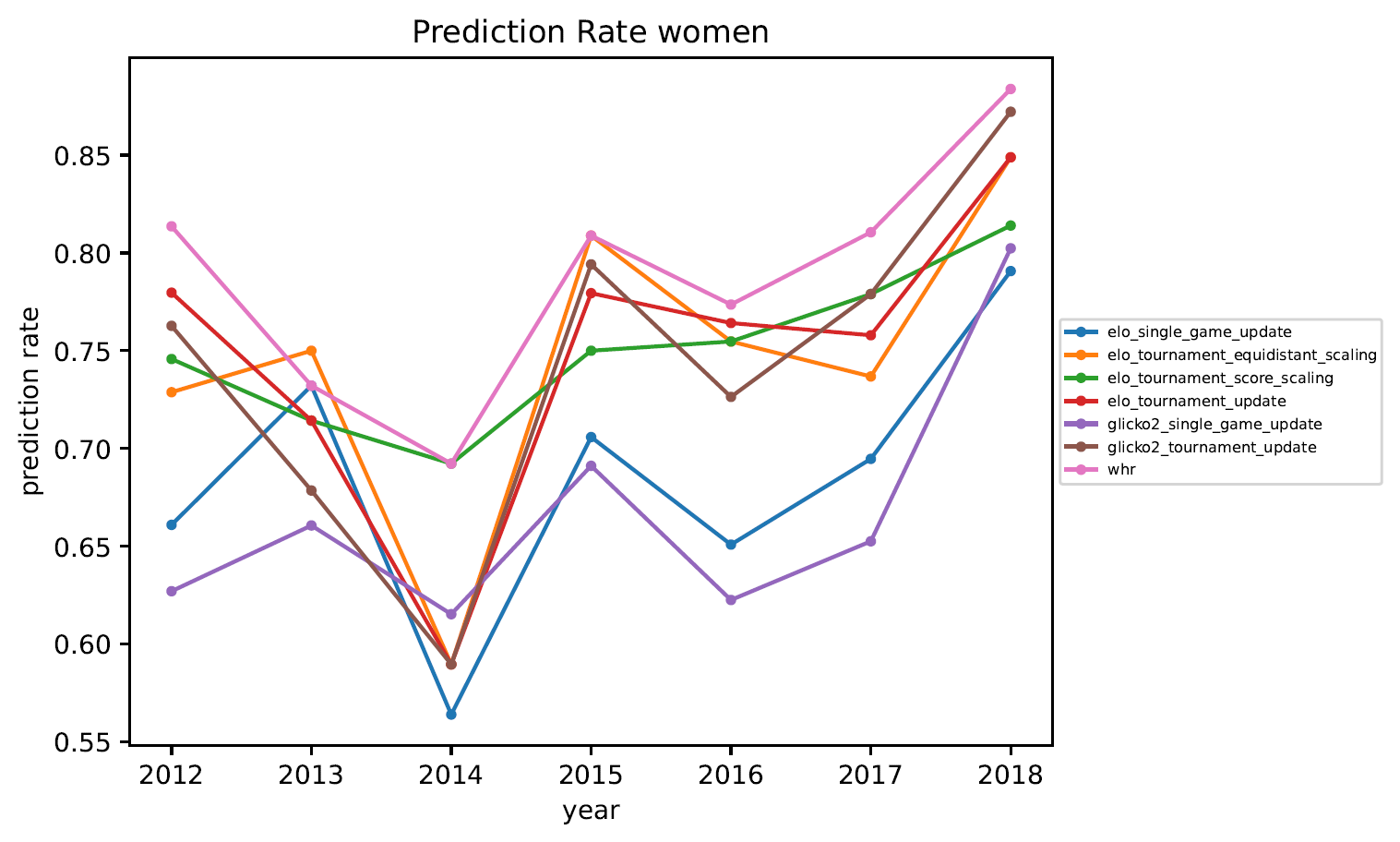
3.5. Vorhersagequote
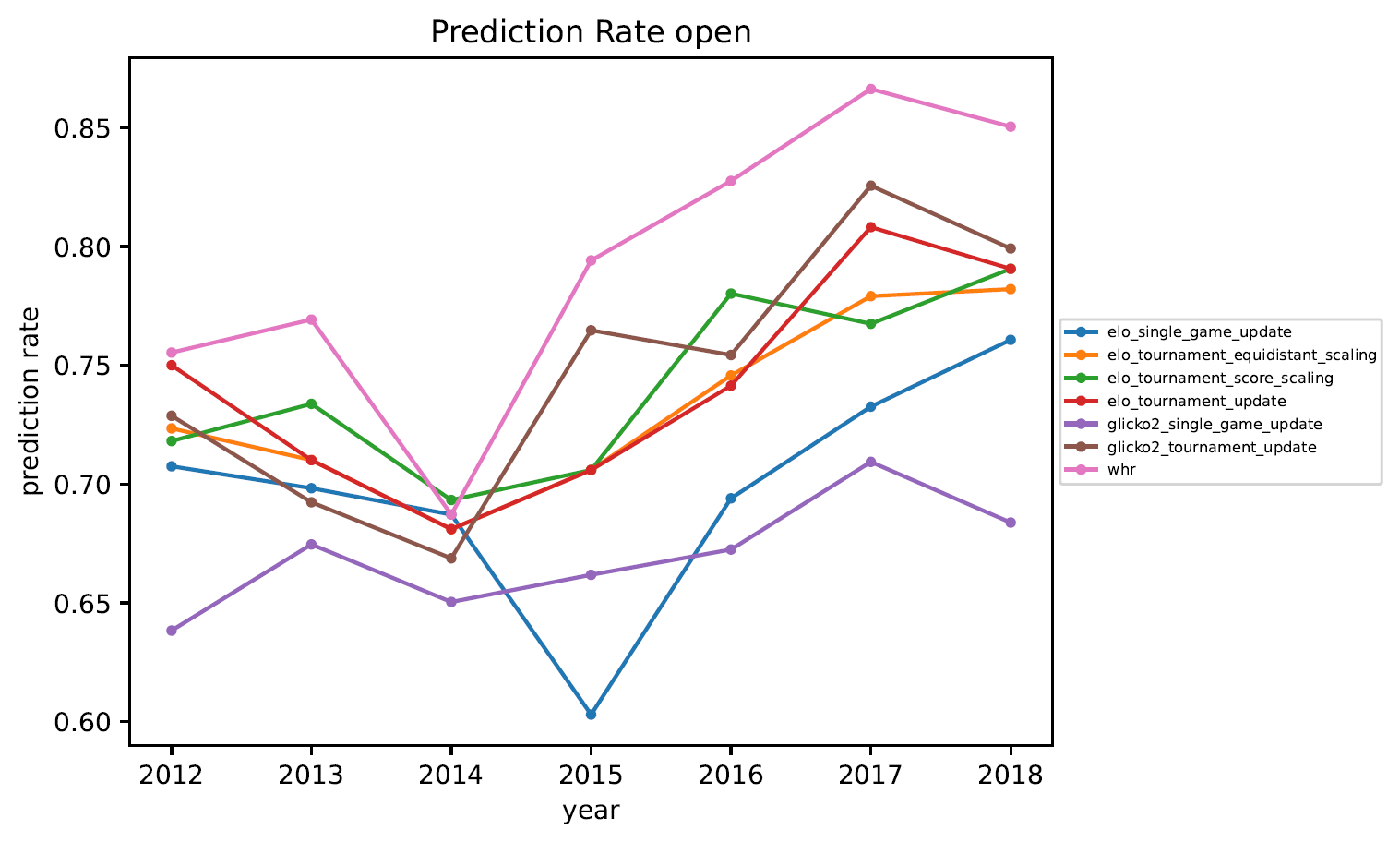
3.6 Interpretation
Allgemein:
- Die Ratings unterschiedlicher Divisionen sind nicht miteinander vergleichbar.
- Wird für ein Team nur für einen begrenzten Zeitraum ein Rating angezeigt, kann das verschiedene Gründe haben:
- Das Team hat nicht alle Saisons von 2011-2019 gespielt.
- Das Team hat sich umbenannt.
- Es kam zu Programmierfehlern bei der Implementierung.
Anmerkungen zur Vorhersagequote:
- Würde man das Rating zufällig verteilen, hätte man eine Vorhersagequote von 50%.
- Im Jahr 2014 war die Vorhersagequote deutlich schlechter als in anderen Jahren. Das ist vermutlich auf die sehr schlechten Wetterbedingungen während der DM in Jena zurückzuführen. . .
- Das Whole-History-Rating erzeugt (wie erwartet) die beste Vorhersage.
- Die verschiedenen Elo-Varianten erzeugen schlechtere Vorhersagen. Je nach Liga liegt die Vorhersagequote eines turnierweisen Elo-Updates etwa 5%-10% unter der Vorsagequote mittels Whole-History-Rating.
4 Fazit
Es ist relativ unwahrscheinlich, einen Rating-Algorithmus zu finden, welcher bessere Ergebnisse als das Whole-History-Rating liefern wird. Im Vergleich zum einfachen Elo-Rating bietet das Whole-History-Rating eine präzisere Vorhersage. Je nach Division ist der Unterschied mehr oder weniger stark ausgeprägt. Diese Verbesserung wird jedoch mit einem deutlich komplexeren Algorithmus erkauft, welcher für den Großteil der deutschen Ultimate-Spieler*innen nicht nachvollziehbar sein dürfte.
Zum Abschluss ein kleines Fazit. Hier können die Meinungen natürlich auseinander gehen, gerade in Bezug auf die Frage, ob die Verbesserung der Vorhersagequote einen komplizierten Ansatz rechtfertigt. Meiner Meinung nach wäre es am sinnvollsten ein ganz klassisches Elo-Verfahren einzuführen, ohne weitere Modifikation wie Gewichtung durch Punktedifferenz. Dieses sehr einfache Verfahren liefert bei sinnvoller Parameterwahl verhältnismäßig gute Vorhersagen und lässt sich sehr einfach implementieren und verifizieren.
5 – Anhang
5.1 Elo – Parameterwahl
Der Elo-Rating-Algorithmus enthält einen Parameter, der kontrolliert, wie schnell sich das Rating ändert. Im Schach sind 16 und 32 übliche Wahlen für diesen Parameter. Alle Plots aus dem Kapitel 3 wurden mit einem Parameter von 80 erstellt. Diese Wahl wurde über sehr naives Parametertuning erstellt, indem für verschiedene Parameter die Vorhersagequote verglichen wurde. Es gab insbesondere keine Aufteilung in Test- und Trainingsdaten oder Ähnliches. Alle folgenden Plots benutzen ein turnierweises Elo-Update für verschieden Parameterwahlen.